Table of Contents
The 2024/25 ecommerce SEO playbook was proven: find keyword volume, map content to it, and track Google rankings. It worked because there was only one surface to optimize for.
In 2026, there are two. Google organic and Google Shopping still dominate ecommerce revenue, for now. But ChatGPT, Claude, Perplexity, and other major AI search platforms are now a second surface, with their own retrieval logic, citation criteria, and failure modes.
The old playbook accounts for none of it, even as more of your buyers start their search there.
If you’re an established DTC or retail brand already winning on Google, here’s the uncomfortable part: none of that Google performance tells you how you’re doing on the second surface. You can be the top organic result for your category and still lose the AI answer—absent entirely, or cited as a source while the model recommends a competitor.
And there’s no single source of truth for LLM retrieval to guide you. GA4 and GSC are starting to surface some signal, but nothing close to what they give you for organic visibility.
Constraint Mapping is how we measure it.
The rest of this page walks through the end-to-end process of Constraint Mapping on two recognizable DTC brands—Bombas and Cotopaxi—so you can see exactly what it surfaces and follow it in your own catalog.
The Three-Step Process (Run on Two Brands)
In May 2026, we ran Constraint Mapping end-to-end across Bombas and Cotopaxi using only public data: three steps and an output.
Here’s each step and what it surfaced.
Step 1. Keyword jobs: Jobs, not search volume
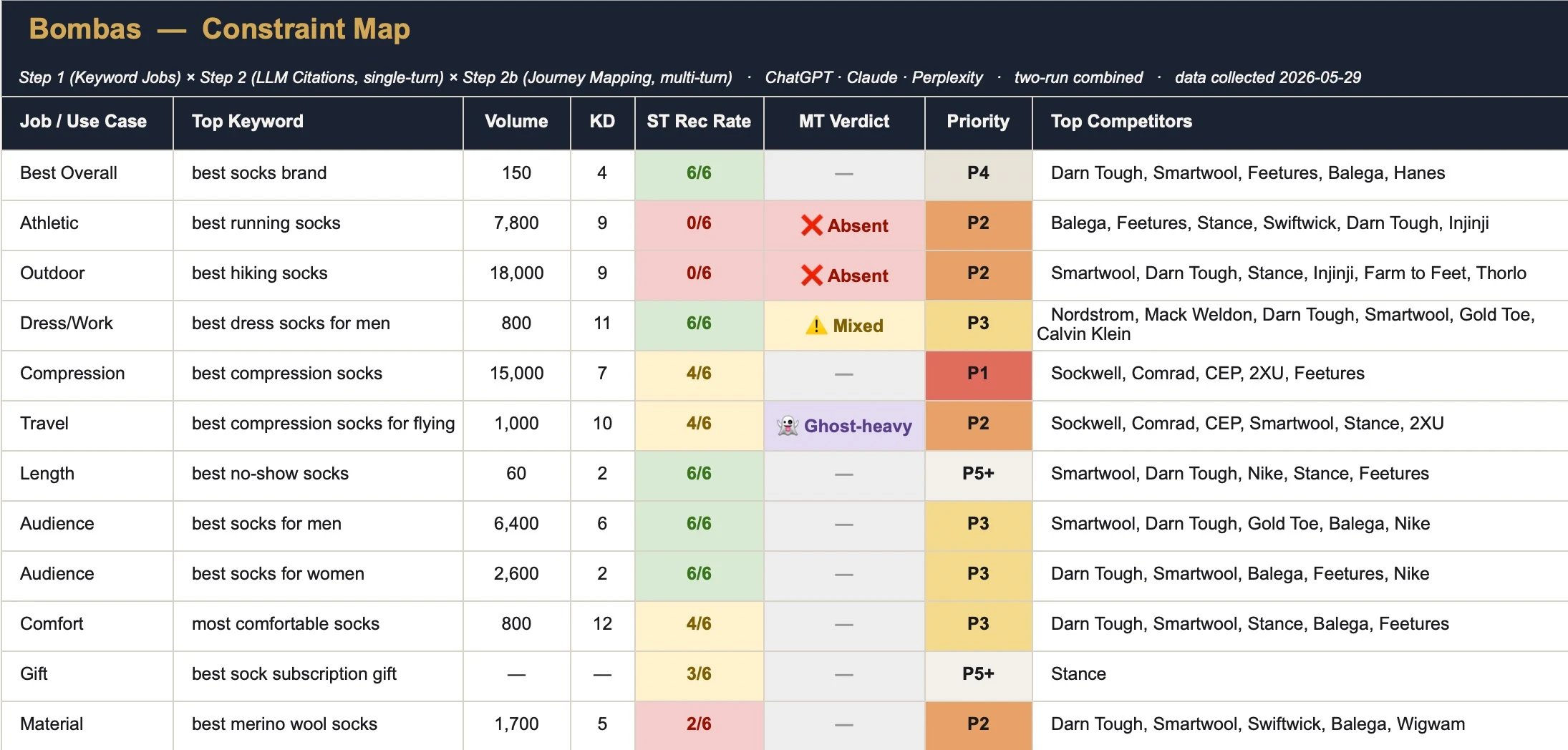
First, we group the revenue-driving queries by the “job” the buyer is hiring the product for, not by catalog or SKU. Each job becomes one row—one constraint—of the Constraint Map, the artifact this audit produces.
A Constraint Map is a table with one row per buyer job, each tested for AI citations both directly and across a full buying conversation, then resolved to a priority and an action. The next two steps fill in the rows.
We borrow “jobs” from Clayton Christensen’s Jobs to Be Done framework: each keyword group represents a job the buyer is hiring your content to do. In this framework, a job is the buyer’s goal—for example, staying comfortable on a long flight—while the keyword is how they express that goal in search. Standard keyword research groups terms by volume and difficulty, which misses the constraints your buyers are actually solving for.
Our ecommerce keyword research guide shows exactly how we find these queries and group them into jobs—it’s the front half of building a Constraint Map.
- Bombas: 12 jobs, sorted into demographics (best socks for men, best socks for women), athletic (running, hiking), and use case (compression for travel).
- Cotopaxi: product categories (fanny packs, slings, daypacks, fleeces, puffies) plus one positioning job (“most sustainable outdoor brand”).
The grouping already matters because, as the next step shows, brands win and lose those groups very differently. The model doesn’t generalize from “Cotopaxi is the most ethical outdoor brand” to “Cotopaxi makes good fanny packs.” Those are separate retrieval problems, so the audit has to work at the job level.
Step 2. Single-turn citations: Does the brand show up when asked directly?
Run each job as a one-shot query, the way a buyer would type it, across the AI platforms—three in this public demo, nine in the client version. Each job gets six tests: three platforms, two end-to-end runs (more on why two runs below). Every result comes back one of three ways:
- Recommended: the brand is named
- Ghost Ranking: the brand gets cited as a source, but a competitor gets recommended
- Absent: no mention at all
Bombas’s single-turn results made the split obvious.
- Recommended six of six on every demographic query: “best socks brand,” “best socks for men,” “best socks for women”
- Recommended zero of six on “best hiking socks” (18,000 searches/month) and zero of six on “best running socks” (7,800 searches/month)
- A brand known for athletic socks. Not recommended for athletic socks.
Cotopaxi showed the same blackout across every product category it sells: zero or one of six on fanny packs, slings, daypacks, fleeces, and puffies, with Patagonia, REI, Osprey, Aer, and Fjällräven in its place.
Step 3. Multi-turn journey: Does it survive the whole buying conversation?
A single query is one moment. It’s also not how people use AI search. A real buyer asks five or six questions in a row. Google’s own AI Mode insights report shows that follow-up queries in AI Mode increased by more than 40% per month on average in the U.S.
So we run select jobs as a five-stage conversation:
Problem Aware → Solution Seeking → Evaluation → Shortlisting → Purchase Intent
Then track where the brand surfaces, where it drops, and who replaces it.
This is the step most LLM-visibility work skips, and it’s where the most useful findings hide: a brand can win the opening question and quietly get cut at Shortlisting. Considered, not chosen.
Cotopaxi is a clean illustration.
Across the “most sustainable outdoor brand” journey, it was recommended in 29 of 30 stages (five stages, three platforms, two runs). It owns that conversation.
Across its product-category journeys, it showed the same blackout pattern Bombas showed in single-turn. The positioning won; the products lost. Same brand, opposite outcomes, depending on the job.
Bombas shows the inverse, and it’s just as useful. In single-turn, “best hiking socks” and “best running socks” returned a flat zero—not recommended, not even cited. The journey told a different story: in each five-stage conversation, Bombas was passed over for a specialist 13 times—considered, never chosen—and still won too few stages to clear the bar. Verdict on both: Absent. Single-turn results made Bombas look irrelevant to the category. The multi-turn journey showed it was being considered, but repeatedly lost out to competitors when it came time to make a recommendation. You only get that second read by running it as a conversation.
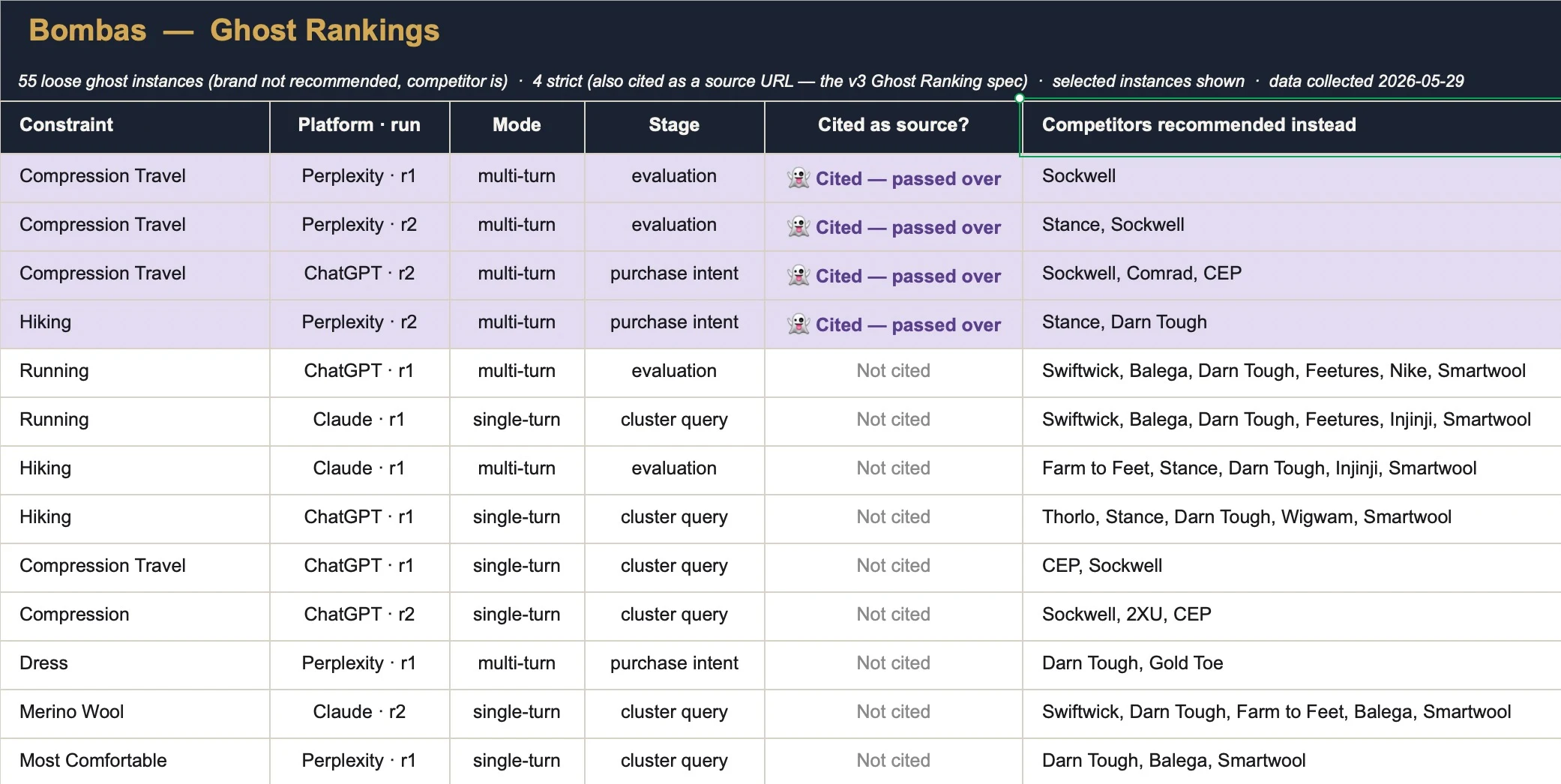
The audit logs every one of those moments. Across both runs, Bombas drew 55 loose ghosts—passed over for a competitor—and four strict Ghost Rankings, where it was cited as a source and still lost the pick. Three of the four are “best compression socks for flying”:
The Output: Priority and action — So what do we work on and when?
Every completed row of the Constraint Map resolves to a priority (P1–P5) and one of three actions:
- Reinforce: cited but not consistently recommended. Add comparison content, journey-stage content, schema, and citations.
- Build: absent on a high-volume job. Nothing for the platforms to retrieve, so build the page from scratch.
- Defend: winning cleanly. Hold it, add schema, prevent erosion. Bombas’s demographic queries and Cotopaxi’s sustainability positioning both land here.
For Bombas, that resolves to specifics, not platitudes: reinforce “best compression socks” at P1 against Sockwell, Comrad, and CEP; build a dedicated /compression-socks-for-flying/ hub at P2 against the same set; build the hiking and running pages from scratch behind those.
That flying hub isn’t a hunch. “Best compression socks for flying” came back ghost-heavy: at several journey stages, Bombas is cited as a source and still loses the pick to Sockwell, Comrad, or CEP—a textbook Ghost Ranking. It already shows up across half the conversation; the converting page just isn’t built yet.
The order isn’t raw search volume.
A job the platforms already half-credit converts faster than one with no surface at all, so a near-miss at high purchase intent outranks a bigger absence that needs a ground-up build.
A generic content audit hands you “improve internal linking.”
A Constraint Map hands you the page to build, the competitors to beat, and the order to do it in.
/compression-socks-for-flying/.That’s the whole process: jobs, single-turn, multi-turn, priority, and action.
Run on any catalog, the Constraint Map returns the same kind of answer per query: where your content lands and where to build when it doesn’t.
And it keeps surfacing the same frustrating pattern: the queries a brand most wants to own are often the ones it doesn’t.
Here’s the whole artifact—one brand’s complete Constraint Map, every job scored and prioritized:
Why These Numbers Hold Up
By now, a fair objection: LLMs are non-deterministic. Can you rerun the same query and get whatever number you want? You can, which is exactly why every Constraint Mapping audit runs end-to-end twice.
Same brand definitions, same constraints, same prompts, same models.
Two independent sessions, two independent reads of the platforms, and the numbers we report are combined across both.
Any count built on a single 96-query session inherits the variance of those 96 responses. One run is a snapshot: it might be accurate, or it might sit at the high or low end of the noise band, and within a single session, there’s no way to tell which.
Two runs tell you whether a finding holds. The Bombas and Cotopaxi audits gave us the reproducibility data behind the method:
-
Multi-turn journey data is highly reproducible. Per-stage signal matched between runs 92% of the time for Bombas and 90% for Cotopaxi, with five to seven points of mean drift.
-
Single-turn data is noisier.
- Mean drift was eight points for Bombas, 19 for Cotopaxi.
- Of 12 single-turn constraints per brand, Bombas had 10 stable, one that drifted, and one that flipped 40+ points between runs.
- Cotopaxi had six stable, five that drifted, and one flip.
- Combining runs removes the risk of reading either one in isolation.
-
Competitor lists are stable. The brands named in place of the audited brand showed a top-five overlap of 0.62 to 0.73 across runs.
The names that take your citation surface show up at the top of both runs, even when individual queries wobble.
The line we hold to: a single-pass LLM audit is a snapshot; a two-run audit is a measurement.
Snapshots get quoted and shared on LinkedIn, but fall apart when someone reruns the query a week later.
If you’re deciding what content to build, optimize, or defend, a snapshot isn’t enough.
When to Run It
Constraint Mapping earns its place before you:
- Brief the content team on next quarter’s editorial calendar
- Decide whether to enhance, cut, or rebuild existing category pages and blog content
- Weigh AI search visibility as a strategic risk or opportunity
- Commit budget to a competitive content build against a specific competitor set
It isn’t a one-shot snapshot to cite once and forget. If a vendor offers an “LLM visibility audit” without explaining how it handles variance across multiple runs, you’re getting a snapshot, not a measurement. That’s not a weaker version of the audit—it’s flawed from the start.
FAQ
How is Constraint Mapping different from a standard SEO audit?
Three ways. A standard audit covers one surface (Google); Constraint Mapping covers Google and the major LLM platforms as separate retrieval surfaces. A standard audit reports findings at the page level; Constraint Mapping reports at the per-query, per-journey-stage level. And a standard audit reports a single pass; Constraint Mapping runs every query twice end-to-end to separate signal from variance.
How many queries does it cover?
The demonstration version runs 96 LLM queries per brand per run: 12 keyword constraints across three platforms in single-turn mode, plus four multi-turn journeys across five stages and three platforms. Two end-to-end runs make that 192 queries per brand, or 384 API calls once citation follow-ups are included (768 across both demonstration brands). The client version covers nine platforms and a brand-specific constraint set sized to the catalog—typically 20 to 40 constraints, which puts the client version well into the hundreds of queries once it runs across nine platforms and two passes.
Is this the same as a Ghost Rankings audit?
No. A Ghost Ranking is one of three possible citation outcomes (the others are Recommended and Absent). A focused Ghost Rankings diagnostic looks at that one failure mode. Constraint Mapping is the full process that surfaces all three states, plus the journey mapping and the priority-and-action output. If you only have time for the focused diagnostic, start there. If you’re making content decisions across the catalog, run Constraint Mapping.
Can I run a version of this myself?
Directionally, yes. The DIY version is in our ecommerce keyword research guide: pick your top five product categories, write the use-case queries a buyer would type, run each through ChatGPT, Claude, and Perplexity, and note whether your brand shows up. That gives you the shape of the absence pattern. It won’t provide journey mapping, the two-run check, per-query priority scoring, or build recommendations with URL specificity. Those are the differences between a directional self-check and a productized audit.
See Where Your Content Is Landing
Constraint Mapping is the method behind the GEO Intelligence Report we deliver to clients: nine AI platforms, a constraint set sized to your catalog, two-run reproducibility, per-query priorities, and build recommendations with URL specificity.
If your content isn’t producing the AI citation surface you need, start with a GEO Intelligence Report.
*
Methodology
The demonstration version (used in the Bombas and Cotopaxi audits) tests each brand across 96 LLM queries per run—12 single-turn keyword constraints plus four five-stage multi-turn journeys, each run twice end-to-end across ChatGPT, Claude, and Perplexity. Models: GPT-4o, Claude Opus 4.5, Perplexity Sonar. The client version covers nine platforms.
Per-call response data and run-by-run comparison workbooks are on file, available on request for any specific claim. Data collected: May 2026.