Table of Contents
Your buyers have started asking AI instead of Googling.
“What are the best baby bath brands?” “Who makes the best running socks?” “I want a yoga mat — what should I get?”
Then the model hands back a short list of names. You’re on it, or you’re not.
So here’s the question every ecommerce brand is now asking: what decides who makes that list?
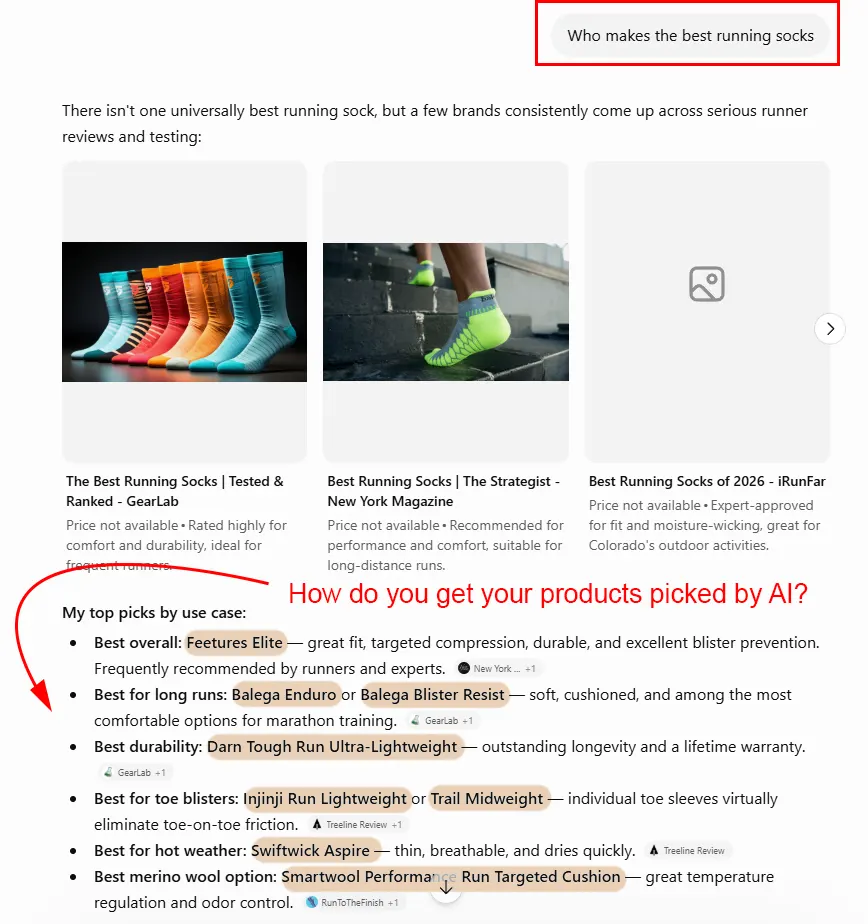
The popular answer, and the one behind our own Category-First SEO, is structure: Organize your catalog the way buyers actually shop, tighten your category architecture, and you earn your place in the answer.
In theory, this makes sense, and it’s what many in the industry are selling right now. We wanted to know if it holds up.
So we tested it. Here’s what we did:
- We pointed three AI platforms (ChatGPT, Gemini, and Perplexity) at 95 ecommerce brands.
- Ran four questions per brand: the three above, plus asking each about the brand by name.
- Ten times each, per platform. That’s 11,400 answers with every flagged call checked by a human, not just a script.
- We swept Google’s AI Overviews separately, 855 checks more; they run alongside the chat results throughout.
The results almost kept this study in a drawer:
Category structure doesn’t affect whether AI recommends you. Not on any platform, not on any dimension we measured.
A null like that feels like a non-finding. Who publishes “the thing everyone’s selling doesn’t work”?
But it might be the most useful number in here. It means the budget you’d pour into restructuring your site for AI is budget you can keep. And the same 11,400 answers showed us what decides who gets recommended. And that’s the part you can act on.
The Baymard Study that Instigated this One
Baymard Institute’s research on homepage and category usability — and its Category Taxonomy report in particular — has documented for years how category taxonomy fails buyers: unclear names, filters posing as categories, and hierarchies organized around the catalog rather than the shopper.
We turned those failure patterns into a 24-point scoring rubric, scored 95 brands on it, and asked a question Baymard’s work never claimed to answer:
Does taxonomy quality predict search and AI visibility?
In March, we ran a 25-brand exploratory study that surfaced five AI visibility patterns. This is the scaled-up version: more brands, more verticals, pre-registered statistics, and a human-review layer for every flagged API call.
The Experiment
95 DTC brands, $10M–$100M revenue, 10 verticals. Each brand scored on a 24-point category-taxonomy rubric, then measured on three visibility surfaces:
- AI chat: ChatGPT, Gemini, and Perplexity (search-enabled), 4 buyer prompts per brand × 10 runs per platform — 11,400 responses, each coded recommended / mentioned / ghost-ranked / absent, dual-pass human review
- Google AI Overviews: 855 measurements (3 prompts × 3 runs per brand)
- Google organic: non-branded keyword capture on category pages, top-75 keywords per brand
Analysis plan locked before data collection. Collection: April–May 2026.
Category structure doesn’t move AI recommendations
This is the one we built the whole study to find. We expected a signal — better-organized catalogs winning more AI recommendations. It’s the thesis behind our own Category-First SEO, and we went in believing it.
The answer is no.
We lined up each brand’s taxonomy score against how often AI actually recommended it. There’s no relationship. A brand with near-perfect category structure is no more likely to get picked than one with a mess of a site — and that holds across both surfaces we measured: AI chat (ChatGPT, Perplexity, Gemini) and Google’s AI Overviews.
It isn’t hiding in one piece of the rubric, either. We scored eight separate things: naming, hierarchy, filter discipline, cross-placement, the lot. Not one of them moved the needle on either surface.
For the data nerds
Taxonomy score × recommendation rate, across all eight rubric dimensions. AI chat: Spearman ρ = −0.074 · 95% CI [−0.27, +0.13] · n = 95. AI Overviews: ρ = +0.058 · n = 95 · both pre-registered, both flat.
If category structure mattered even a little — half as much as the GEO-advice crowd implies — it would have shown up here. It didn’t, on either surface. And we committed to this exact test before collecting a single answer; a positive result would have been published just as fast.
If someone is selling you taxonomy work as a GEO play, the evidence says no. (Where it does pay — measurably — is the last thing we’ll show you.)
It’s not raw branded search demand either
The obvious pushback writes itself: of course, structure doesn’t matter, AI just recommends the brands people already search for.
So we tested that too. Pulled the US monthly search volume for all 95 names and lined it up against the recommendation rate.
Flat again. A brand that is searched 100,000 times a month gets no edge over one that is searched 3,000 times. (Strip out the brand names that double as common words — your seeds and rituals — and a faint pull appears, but nothing you’d build a plan on.)
The brands tell it better than any number does:
- Manduka: 10K searches a month, recommended in 76% of yoga-mat answers.
- Solly Baby: 3.6K searches, 73%.
- Drunk Elephant: 100K searches a month, mentioned in 0% of premium-skincare answers. The models reach for La Mer, SkinCeuticals, and Tatcha, and act like one of DTC’s most famous brands doesn’t exist.
For the data nerds
Branded search volume (Ahrefs US) × recommendation rate. ρ = +0.07 · n = 95 · clean-name subset ρ = +0.22 (n = 67, not significant). Indig’s mentions × popularity, for comparison: r = 0.334.
Kevin Indig found that brand popularity was the strongest predictor of AI mentions, and we’re not arguing with him. His sample ranged from category giants to unknowns, and popularity clearly separated those tiers.
Our data adds the part that matters if you’re a $10–100M brand: inside that band, more search demand buys you nothing on the shortlist.
One caveat: search volume is just one piece of brand strength. Press coverage, social presence, and how widely you’re written about — these all matter to some degree, but are not measured here.
What we can rule out is the simple version: more brand searches do not equate to more AI recommendations.
A pattern we’re watching, not something we’ve proven yet: the brands that win at this scale are the ones that are a category — Manduka means yoga mats — not the ones that are simply bigger. Our March study pointed the same way: the brands that showed up cleanly all owned a category in the model’s mind. We saw it across 25 brands at the time. We see it again across 95 now.
Mentioned is not chosen
Across 8,549 answers, brands were mentioned 44% of the time and recommended just 16%.
The distance between those two — how often AI names you versus how often it actually picks you — is what we call the Recommendation Gap.
Among brands that show up at all, the median brand converts only 27% of its mentions into recommendations.
This spread is worth noting:
- tentree: in nearly nine of ten answers, as context, as a comparison, as “you could also look at.” The pick in 3%.
- Glossier: mentioned 30%, recommended 1%.
- And at the other end, Darn Tough and Chomps convert 100% of their mentions into recommendations. (Darn Tough is the same brand that kept taking Bombas’s shelf in our Constraint Map audit. The data keeps electing the same specialists.)
For the data nerds
8,549 discovery answers · 95 brands. Mention rate 44% · recommendation rate 16%. Median conversion among visible brands: 27% of mentions → recommendation.
This is Ghost Rankings confirmed at scale (cited but not chosen), across 11,400 answers instead of 450. The strict Ghost Ranking (your content sourced, a competitor named in its place) is the rare tail.
The Recommendation Gap is the iceberg under it: the wide, ordinary space where you’re visible and just not picked. That’s where most mid-market brands live.
If your AI report counts mentions, it’s measuring the flattering number. Your Recommendation Gap — how much of that visibility actually converts — is the one tied to a buyer’s shortlist.
Your vertical sets your ceiling
We used the same prompts and coding across ten verticals. And we found a 7-fold spread between top and bottom:
For the data nerds
Vertical alone explains ~24% of the brand-to-brand variance in recommendation rate — more than any structural factor we measured · ≈10 brands per vertical. Per-vertical numbers are descriptive, not significance-tested.
The vertical you’re in accounts for about a quarter of the gap between brands. This is more than any other structural factor we measured. It tracks who owns the prompt space.
Ask about rucking gear or yoga mats, and mid-market specialty brands own the answers.
Ask about premium skincare or fine jewelry, and the LLMs reach for luxury brands and mass market incumbents, no matter what structure your site follows.
Across ten brands per vertical, what you see is a pattern, not a significance claim. We report the numbers as descriptive — don’t read real significance into any single vertical’s percentage.
A 15% recommendation rate would be a crisis in pet supplies. It would be a win in beauty. Pick your peer set before you grade your performance.
The platforms agree on who exists — not on who to recommend
Run the identical prompts through all three, and the recommendation rates split:
- Recommended: Perplexity 22.6% · ChatGPT 15.1% · Gemini 10.5%
- Mentioned: all three within four points (42–46%)
Visibility is shared across AI search platforms. They surface the same brands and disagree on whether to commit to a pick.
Outright yes: 1–3% · Hedged “it depends”: ~74%
For the data nerds
Recommendation rate: Perplexity 22.6% · ChatGPT 15.1% · Gemini 10.5%. Mention rate: 42–46% across all three · ~2,850 answers per platform. Direct “is it worth buying?” prompts: outright yes 1–3% · hedged ~74%.
But when you ask them straight-up branded questions — “Tell me about [brand]. Worth buying?” — they get closer together.
- An outright “yes” 1–3% of the time.
- A hedged “it depends on your needs” about 74% of the time.
- None of them wants to put their name on a recommendation.
I’m fascinated to see how/if this changes as ads roll out further across all platforms.
A single blended “AI visibility score” buries these findings. Track each platform separately, and read direct-question hedging as the default — not a problem with your brand.
Your GEO dashboard is probably miscounting
By now, you’ve seen what decides AI recommendations, and what doesn’t. Here’s the part that should worry you: your current tools would have missed most of it.
We almost led this whole piece with this: Perplexity ghost-ranks brands at fifteen times the rate of ChatGPT. That’s a 10.5% Ghost Ranking rate, compared to ChatGPT’s 0.7%.
But it was wrong, thankfully. And the way it was wrong is why you can’t take most AI-visibility dashboards at face value.
Our rules-based classifier automatically matched brand names against all 11,400 answers. And every GEO tool does, because at volume, you have no choice. Then a human checked the flags and found something crucial:
- 261 auto-flagged Ghost Rankings.
- 228 were recommendations the matcher missed. Just seven of them were real.
- 5,075 answers it filed as “mentioned, not recommended.”
- 585 were recommendations — misfiled.
- Fold the corrections back in and the study’s headline finding doesn’t just shrink. It reverses — from a positive to the flat line you read earlier.
For the data nerds
261 auto-flagged Ghost Rankings → 228 were recommendations, 7 real. 585 of 5,075 auto-coded “mentions” were recommendations, on review. Human review reversed the study’s headline correlation (Δρ = 0.22). Strict Ghost Rankings confirmed: 9 of 8,549 answers (0.2%).
A miss like that isn’t random noise — noise averages out. This one pointed somewhere: it built a clean platform-level story (Perplexity, the ghost-ranker) out of nothing but unmatched aliases. Every number in this study went through human review for exactly that reason.
A Ghost Ranking occurs when AI cites your content as a source and then recommends a competitor in the same breath.
Before a dashboard number reallocates your budget, ask yourself one thing: has a human read and verified these answers? If not, your budget decisions could be based on a string match issue, not a marketing one.
Where structure does pay off: Google’s category surface
Here’s the turn. The same rubric that predicts nothing on AI surfaces predicts something real on Google — specifically, whether your category pages pull in non-brand search traffic.
- Clear category naming was the standout. Brands that name categories the way buyers actually search for them capture more non-brand traffic to those pages — the single strongest result in the whole study.
- A couple of other dimensions were helpful but didn’t hold up firmly, and two came back negative — a quirk of how we measured them, not a real effect (the methodology explains it).
For the data nerds
Clear category naming × non-brand category keyword capture. Spearman ρ = +0.328 · n = 87 · survives multiple-comparison correction. Strongest single correlation in the study · two dimensions negative (a measurement artifact).
There’s a quiet symmetry in that. Of the eight dimensions we built from Baymard’s work, the one that pays off in search is the one closest to their original advice: name your categories what buyers actually call them. Baymard’s UX finding turns out to be an SEO finding. It just isn’t a GEO finding.
And that’s the whole picture this study leaves you with.
Category structure is a search lever. It moves the surface that still drives most ecommerce revenue, and we can now name the dimension that moves it most.
AI recommendation runs on other signals. Your vertical, what you’re synonymous with, each platform’s temperament — and none of the structural factors we measured touch it.
Optimize one surface with the other’s playbook, and you waste budget in both directions.
We re-ran a fifth of the study six weeks later
The pages AI tools cite turn over fast. Recent SISTRIX data clock ChatGPT replacing 74% of its cited sources weekly, and Google’s AI Mode at 56%.
So in mid-June, we remeasured: 2,850 fresh answers, the same three platforms, the same models, the same human review.
It held. The brands AI recommended in April were almost entirely the same as those it recommended in June. Recommendation rates moved about a point. AI Overview inclusion barely budged.
If you’re tracking AI visibility, measure the thing that persists — and date everything, because on this surface, undated numbers are fiction.
For the data nerds
Per-brand ranking correlation April → June: Spearman ρ = 0.73. Recommendation rate moved 7.1% → 7.2%. AI Overview inclusion moved 53.6% → 56.4%.
What we learned, in seven lines
- Category structure doesn’t move AI recommendations: no link on either AI surface, a result we committed to testing before we collected the data.
- Neither does branded search demand within the $10M–$100M band: being the name for a category looks like what matters.
- Mentioned ≠ chosen: a 44% mention rate converts to just a 16% recommendation rate — so for now, the Recommendation Gap holds water.
- Your vertical sets your ceiling: 34% vs. 5% on identical prompts.
- Platforms agree on who exists, not who to recommend: Perplexity picks at double Gemini’s rate.
- 87% of auto-detected Ghost Rankings were false: human-review your GEO data before acting on it.
- Structure pays on Google: clear category naming is the cleanest lever we found — on search, not AI.
If you want to know where your brand sits in those numbers — which jobs you win, where you’re considered but not chosen, who’s taking your shelf — that’s the audit our Constraint Map walks through on two real brands, and what the GEO Intelligence Report runs at full depth.
*
The study, in brief: 95 DTC ecommerce brands ($10M–$100M, US/Canada, 10 verticals), each scored on a 24-point category-taxonomy rubric based on the Baymard Institute’s research.
We measured visibility three ways: 11,400 AI chat answers across ChatGPT, Perplexity, and Gemini (4 prompts × 10 runs each), 855 Google AI Overview checks, and category-page keyword capture on Google.
Outcomes were auto-coded and then human-reviewed; the analysis was pre-registered before we collected the data, and we re-measured six weeks later in June.
The numbers are dated on purpose — April–June 2026 — because on a surface that moves this fast, undated data is fiction.