Table of Contents
Duplicate content is more than just a technical issue—it’s eating into your traffic.
Whether it’s messy filters, multiple versions of the same product, or your CMS creating too many similar URLs, duplicate content is silently sapping your visibility in search.
Search engines don’t want five versions of every page. When your site provides several versions of the same page, Google has to process them and pick the main one—the canonical URL.
Doing this costs Google MONEY, and you VISIBILITY. Google picks the one it thinks is best, which might not be the one you want ranking.
That’s where canonicalization steps in. It’s your way of saying:
When I started dealing with duplicate content, Panda and Penguin were the most dangerous animals in the world—or at least in SEO.
In the decade since, I’ve seen a lot of right and wrong ways to approach canonicalization. I’ve made many mistakes myself and learned some hard-earned SEO lessons.
In this article, I’ll tell you everything I know about canonicalization, how to use the canonical link tag, and common mistakes I see in our clients’ websites (and our own).
Canonicalization in 30 Seconds
Canonicalization is a process for managing duplicate content for search engine optimization.
There are many reasons why a site has multiple pages showing the same content. Some of them are legitimate, others result from a poor technical setup.
Regardless of the reason, Google is only interested in indexing and ranking one URL for every page on your site.
Here’s why from Google’s POV:
- Crawling, processing, and storing duplicate pages is a waste of resources.
- Ranking multiple pages with identical content creates a poor search experience.
- The algorithm has to choose which copy is the main page to serve in search.
And here’s why, from the site owner’s POV:
You don’t want Google’s algorithm to make that decision for you because there’s no guarantee it’ll pick the version you want users to see. Even worse, if multiple versions do show up in search, your SEO “equity” gets diluted. Instead of one strong page, you end up with several weaker ones competing against each other.
Canonicalization improves search engine efficiency by correctly annotating duplicate content and helps serve the content YOU WANT in search.
But, let’s hear it from the Google itself:
“Canonicalization is the process of selecting the representative—canonical—URL of a piece of content. Consequently*,* a canonical URL is the URL of a page that Google chose as the most representative from a set of duplicate pages*.”*
The second part is important. It’s Google that performs the canonicalization, not the website owner.
But we do have a say! Google provides us with a number of methods to express our preference for the canonical URL, starting with:
The Canonical Tag
It looks like this:
<link rel="canonical" href="https://example.com/dresses/green-dresses" />We use it to let Google know the preferred URL (canonical URL) for this page/content.
For most of your site, a given page’s URL and its canonical URL are the same.
If your page is: https://example.com/handyman-services/
The canonical URL is also: https://example.com/handyman-services/
Let’s say you have two duplicate pages:
https://example.com/handyman-services-copy/https://example.com/handyman-services-2/
The canonical URL is again: https://example.com/handyman-services/
The canonical tag should be added to your website’s section on EVERY PAGE. This is known as self-canonicalization, and it’s your first line of defense against duplicate content.
Modern CMS platforms generate hundreds or even thousands of duplicate URLs, most of which add no search value. Canonical tags prevent this overload from harming your SEO.
Some duplicate content is unavoidable. The canonical link is especially important for dynamically generated pages like:
Product versions: Ecommerce platforms usually rely on URL parameters to differentiate between product variants like size, color, or other options.
Example: https://aedadvantage.ca/products/philips-heartstart-onsite-aed?variant=42604355059883
Dynamic category URLs: Category filters and tags frequently use different URLs to change the order of product listings.
Example: https://www.pedaal.com/store/folding-bikes/?\_product\_tags=acoustic-bikes&\_handlebars=low&\_product\_price=2565.00%2C4230.00
Search pages: Search results pages use dynamic URLs to serve the infinite number of searches you can type.
Example: https://cmaexamacademy.com/?s=accounting+formulae
Tracking parameters: Duplicate URLS with appended characters that track the user’s path and journey throughout the site.
Example: https://digitalcommerce.com/?utm\_source=externalBlog&utm\_medium=content&utm\_campaign=Blogref&utm\_id=inbound231
Here’s where the canonical link plays a critical role:
If the main page has a canonical tag set up to itself, dynamically generated pages usually inherit it, and the canonicalization occurs automatically.
Other forms of duplicate content are just technical dead weight. I’m talking about:
- HTTP vs HTTPS
- WWW vs non-WWW
- Forward slash vs non-forward slash
There are still technical reasons why these URLs may exist, but there’s no reason for them to be accessible to users and crawlers. Given the opportunity, we should always redirect all possible combinations to a unified URL consistently used across the site.
But if you can’t redirect them, proper canonicalization to the preferred variant will resolve the duplicate content and improve resource spend for search engines.
When Canonical Links Don’t Work
The canonical link is a suggestion, not a directive. If other factors weigh in, Google can and will assign a different canonical URL.
The canonical tag only works on duplicate, near-duplicate, and dynamic content. Any significant deviation in the main body of content will likely result in Google recognizing two different pages.
Don’t Canonicalize Topically-Similar, Non-Duplicate Pages
For example, consider two articles on the same topic, but written independently of each other. They carry the same paraphrased basic information.
You don’t want both ranking for the same keyword. That’s keyword cannibalization.
However, they are not duplicate pages, so Google will most likely ignore the canonical link.
The proper way to deal with these pages is either redirecting or de-optimizing/re-optimizing one of them to resolve the competition.
Don’t Canonicalize Paginated URLs to the Main
Here’s something I’ve been guilty of doing for years: Paginated URLs shouldn’t point their canonical tag to the main category page—they should reference themselves instead.
Depending on your website platform and setup, your category pages may be split into multiple sub-pages, each showing a set number of blog or product listings.
Here’s what I’m talking about:
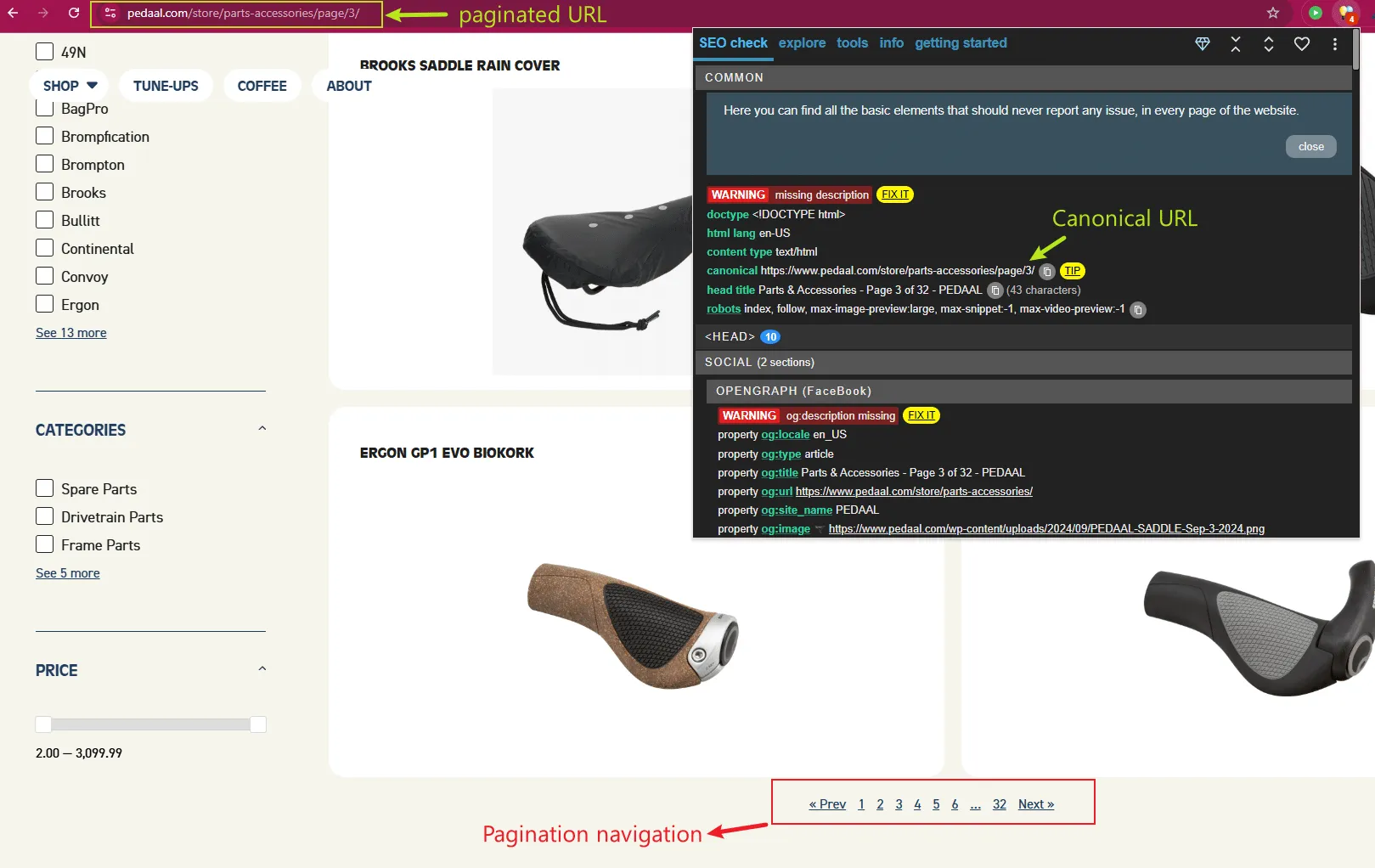
Pedaal’s online store sells quite a few bike parts and accessories under this category URL: https://www.pedaal.com/store/parts-accessories/
We don’t want them ALL to load at the same time because users will have to suffer a significant delay for no practical benefit. So, we only load the first dozen, after which users can navigate to sub-pages to browse more.
There are 32 paginated URLs, like this one: https://www.pedaal.com/store/parts-accessories/page/3/
I used to believe they should be canonicalized to the main category URL, and I’ve implemented it this way for years.
This was my reasoning:
- These pages have zero value for search. They don’t present any unique content, and their content will vary as the items in the category expand or change.
- I don’t need them indexed, and would like to rank for any relevant keywords with the main category URL.
- They are not any more UNIQUE than category pages with applied filters, for example.
But here’s the truth:
- These pages are not duplicates of each other. They present different parts of the entire catalogue.
- You don’t necessarily want these pages in the index, but it doesn’t usually hurt your search performance. If they appear in search, it’s because their content reflects the search term used. Even when you remove them, there’s no guarantee the main category URL will pick up the slack, as it doesn’t list this specific content.
- Canonicalizing them can hinder crawling and discovery.
Here’s what Google says on the matter:
“Don’t use the first page of a paginated sequence as the canonical page. Instead, give each page its own canonical URL.“
You want Google to crawl paginated URLs actively and discover all of your blog or product listings. If you canonicalize them, and Google accepts them as duplicates, it will stop crawling them regularly.
If the paginated URLs are the only way to discover your content, canonicalizing them can lead to problems with slow or a complete lack of indexation.
If you absolutely don’t want paginated URLs to appear in search, add a meta robots tag, like so:
<meta name=”robots” content=”noindex,follow”>Working with Canonical Tags
Now that you understand what the canonical link does and what it doesn’t do, working with them is actually very easy.
You just place the link tag in the <head> section of your page, like so:
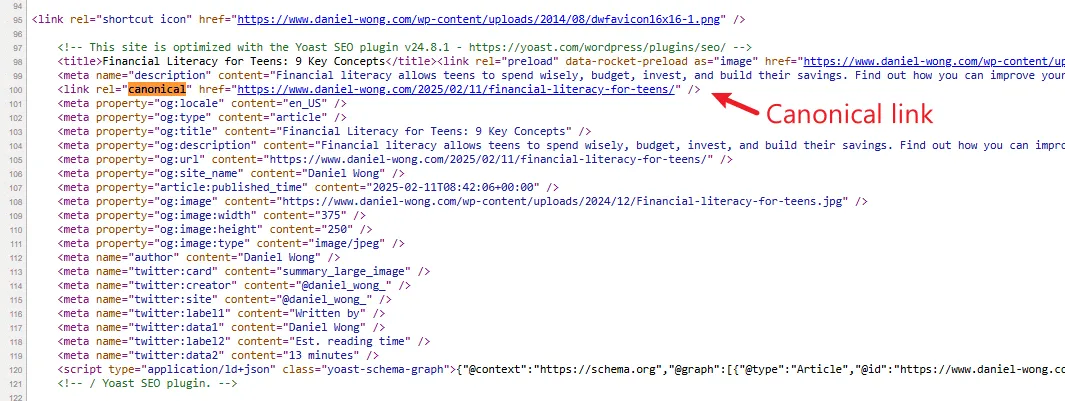
<link rel="canonical" href="https://www.example.com/my-canonical-url">And here’s an actual canonical tag example from one of our clients’ sites:
There are only a few basic rules here:
Do:
Place Canonical Tags in the Section
Google only accepts the rel=“canonical” link if it’s placed in the of the page.
Don’t:
Add Multiple Canonical Tags on the Same Page
Every page should only have one canonical URL.
Do:
Use Self-Referencing Canonicals on Every Page
Self-canonicalization resolves the vast majority of duplicate content issues.
Modern content management systems do this automatically.
If your site is based on PHP, it’s relatively easy to add the canonical link dynamically in the page template.
Don’t:
Use Multiple (canonical) URL Versions
Consistent internal linking is key for reliable canonicalization.
- Use HTTPS and not HTTP!
- Use either WWW or non-WWW, depending on your preference. But not both.
- Similarly, use forward slash “/” at the end of a URL, or no slash. But not both.
Pick one version and stick with it for ALL your internal links, navigation, canonical URLs, etc.
Do:
Always Use Absolute URLs
Use the full URL, including the HTTPS protocol, subdomain (if any), and the complete path to the final page.
Like so: https://digitalcommerce.com/services/generative-engine-optimization/
Relative paths open possibilities for errors.
Don’t:
Block Canonicalized Pages in Robots.txt
Robots.txt prevents crawlers from accessing the page and, therefore, discovering its canonical URL or any content it has or links to.
Allow bots to crawl canonicalized pages.
Do:
Canonicalize Duplicate and Near-Duplicate Content
This includes:
- Product versions
- Categories with filters applied
- Search pages
- Dynamical-generated tracking URLs
- HTTP vs HTTPs
- WWW vs non-WWW
- Forward slash vs no slash
- Staging domains or other copies of your site
Don’t:
Use Canonicals for Non-Duplicate Content
If the content between the two pages is not sufficiently identical, Google will simply ignore the canonical link.
You can’t use canonicals as redirects or to resolve keyword cannibalization.
Paginated category URLs are NOT duplicate content.
Do:
Canonicalize Cross-Domain Duplicates
If you republish your content on multiple sites or syndicate content from a 3rd party source, you can indicate the original version with the canonical link.
Don’t:
Point Canonicals to 3xx, 4xx, 5xx, noindex, or Canonicalized Pages
You’re sending mixed signals. The canonical tag should only point to a live page that returns a 200 Found status code and is indexable.
You should not create chains of URLs that canonicalize to the next. Trace the chain and use the FINAL URL as a canonical for the rest.
Using Canonical Tags in HTTP Headers
The rel=”canonical” link can only be used in HTML pages.
If you also publish content in other formats, like PDF, Word Documents, etc., you can use HTTP headers to provide a canonical link for that content.
Here’s how it looks:
HTTP/1.1 200 OK
Content-Length: 19
...
Link: <https://www.example.com/downloads/white-paper.pdf>; rel="canonical"
...Working with HTTP headers goes into developer territory, so let’s leave it at that.
Canonical Links in WordPress
Like most modern website platforms, WordPress handles self-canonicalization by default.
Even on a brand new WordPress site, you’ll find that your pages, blogs, categories, and products correctly list the canonical tag.
For example:
- Self-Canonical:
https://cmaexamacademy.com/best-cma-study-materials/ - Self-Canonical:
https://boutiquejapan.com/trip-planning/ - Self-Canonical:
https://www.pedaal.com/store/folding-bikes/ - Canonicalized:
https://www.pedaal.com/store/folding-bikes/?_product_tags=e-assist-bikes
Of course, you probably already have an SEO plugin installed on your WordPress site. And if not, that’s the first thing you want to do.
All major SEO plugins allow you to set your own canonical for a given page.
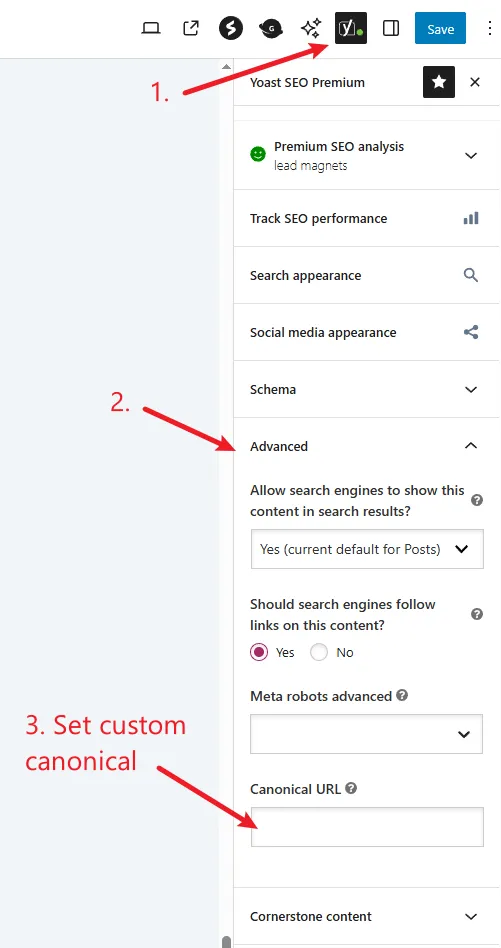
How to set custom canonical links in Yoast SEO:
- In the post editor, navigate to the Yoast SEO settings
- Expand the Advanced tab
- Paste the link in the Canonical URL field (by default, canonical points to self)
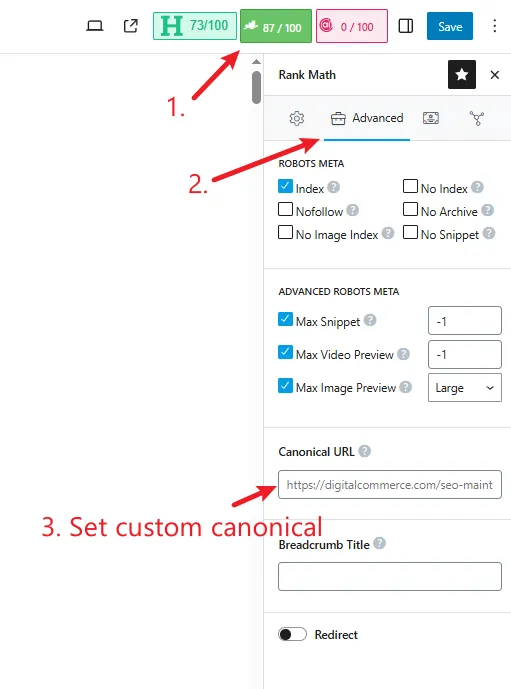
How to add a canonical tag in Rank Math:
- In the post editor, navigate to the Rank Math settings
- Expand the Advanced tab
- Paste the link in the Canonical URL field (by default, canonical points to self)
What sets WordPress apart from all other website platforms is the ability to access the theme code and modify any parts you want, including how the canonical tag is applied.
The opportunity to optimize also comes with the opportunity to break your website. So, be warned about haphazardly messing with your theme files.
Canonical Links in Shopify
Shopify makes canonicals very easy by simply not giving you the ability to control them.
For the most part, though, it’s taken care of for you. For example:
- HTTP goes to HTTPS automatically
- WWW redirects to non-WWW
- And while pages load with and without a slash at the end, they have the correct canonical to alleviate the duplication.
All products, categories (collections in Shopify), pages, and blog posts are self-canonicalized by default, which means:
- Product variants are correctly canonicalized to the main product:
- Canonical:
https://printfresh.com/products/garden-district-gilmore-blouse-carribean-blue - Canonicalized:
https://printfresh.com/products/garden-district-gilmore-blouse-carribean-blue?variant=41447163068550
- Canonical:
- All category filter URLs are correctly canonicalized to the main category:
- Canonical:
https://printfresh.com/collections/blouses - Canonicalized:
https://printfresh.com/collections/blouses?filter.p.tag=Garden+District
- Canonical:
- Even the collection-aware product URLS are properly canonicalized, though that’s no excuse for having them enabled on your site!
There’s no direct way to set a custom canonical link of a given page, unless you install an app like the Canonical Tag URL Wizard or Easy Canonical Links (no affiliation).
Auditing Canonical Links
You can’t fix what you can’t measure. So, let’s talk about the tools we use to discover and diagnose problems with canonicalization:
Using Google Search Console
Google Search Console is our most powerful tool for diagnosing indexing problems.
To check for canonicalization problems, go to Indexing and scroll to the section “Why pages aren’t indexed.”
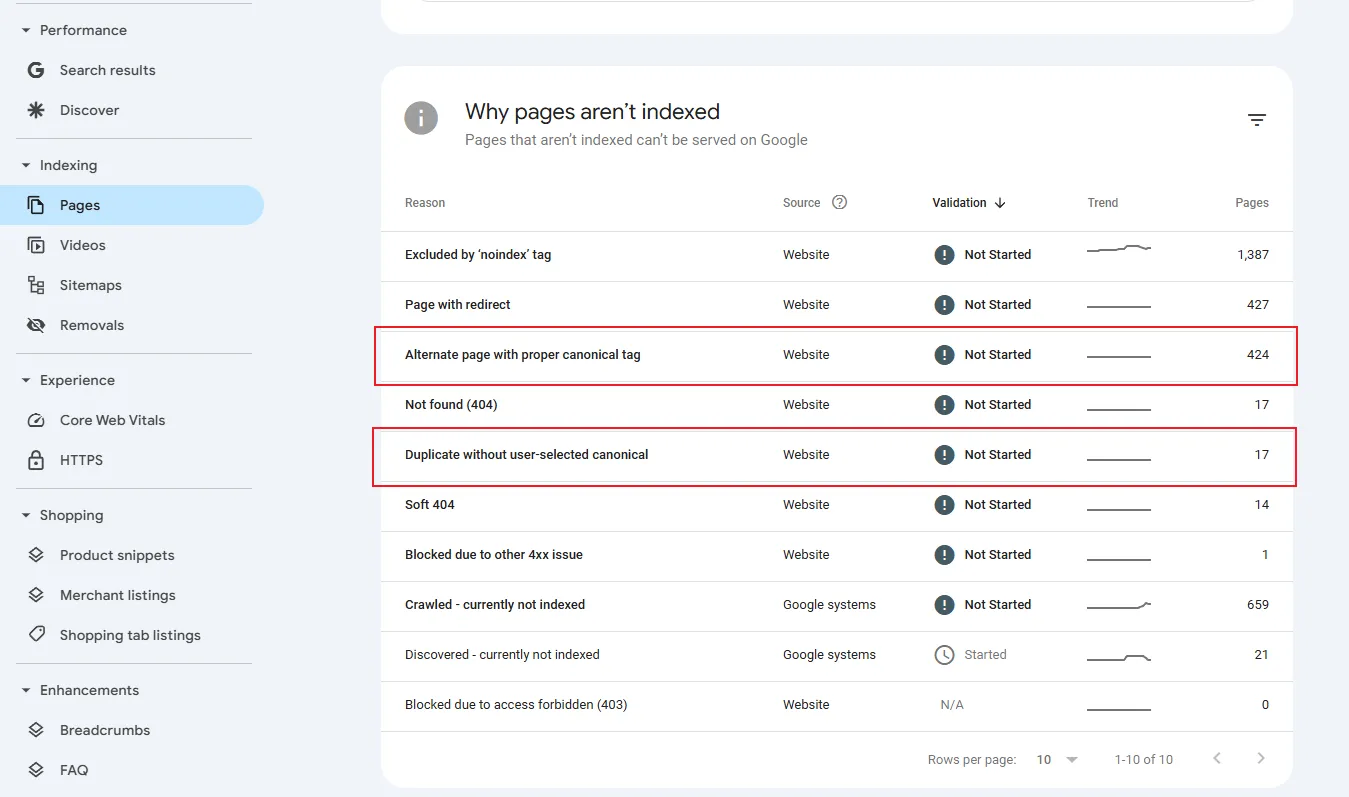
Two labels here are especially useful for evaluating how well your canonical tags are working:
Alternate page with proper canonical tag: This is the result of proper canonicalization. These duplicate pages have been discovered but have not been indexed. Google has found the correct canonical tag. This number can be as high as needed.
Duplicate without user-selected canonical: This category will show duplicate content that doesn’t have a canonical link specified. You want the number of pages here to be as small as possible. You likely won’t get them down to 0, but you should audit this section and implement the correct canonical, redirect, or noindex where it makes sense.
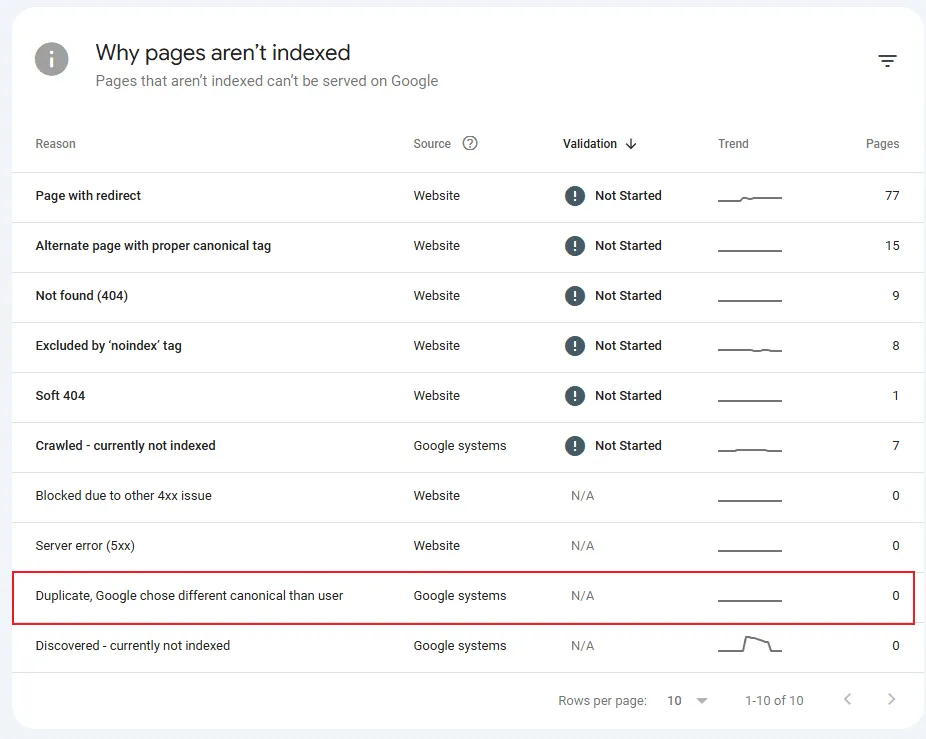
You may also find this section:
Duplicate, Google chose different canonical than user: When Google disagrees with your canonical link, you’re likely doing something wrong—either sending mixed signals or incorrectly applying the canonical. Audit this section and remedy the listed pages.
Duplicate content can make its way into the index, too.
Compare the number of pages in your sitemap.xml to the number of indexed pages by Google:
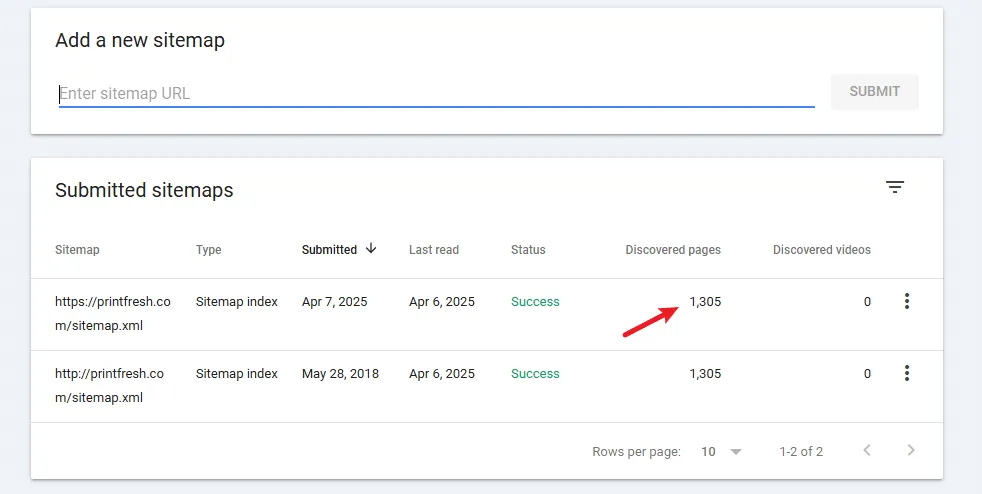
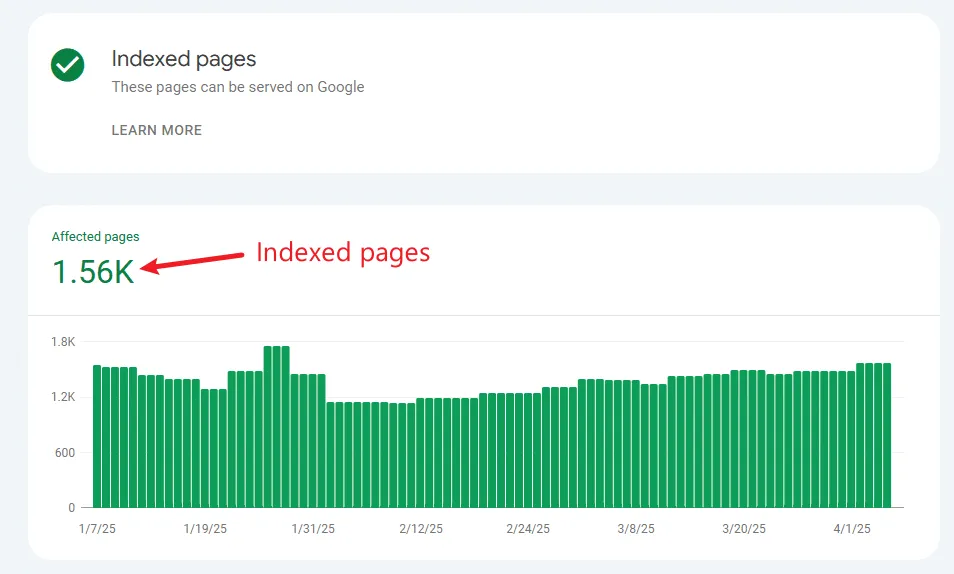
- Sitemap pages - 1.3K
- Indexed pages - 1.56K
If your sitemap has more URLs than Google, you have indexing problems.
You want the indexed pages to be relatively equal to your sitemap URLs. It’s usually more, as Google discovers some content that you don’t necessarily want in your sitemap.
However, if Google indexes twice as many URLs as your sitemap, you should assess whether they all belong there. Google is pretty good at finding and canonicalizing duplicates, but it’s not perfect.
The graph is also helpful in identifying how trends are moving and when an issue began.
You can revisit this report and start a validation procedure when you’re done fixing. Google will recrawl these URLs and look for the canonical tag, then process them accordingly. You can monitor the graph over time to see how the trend moves.
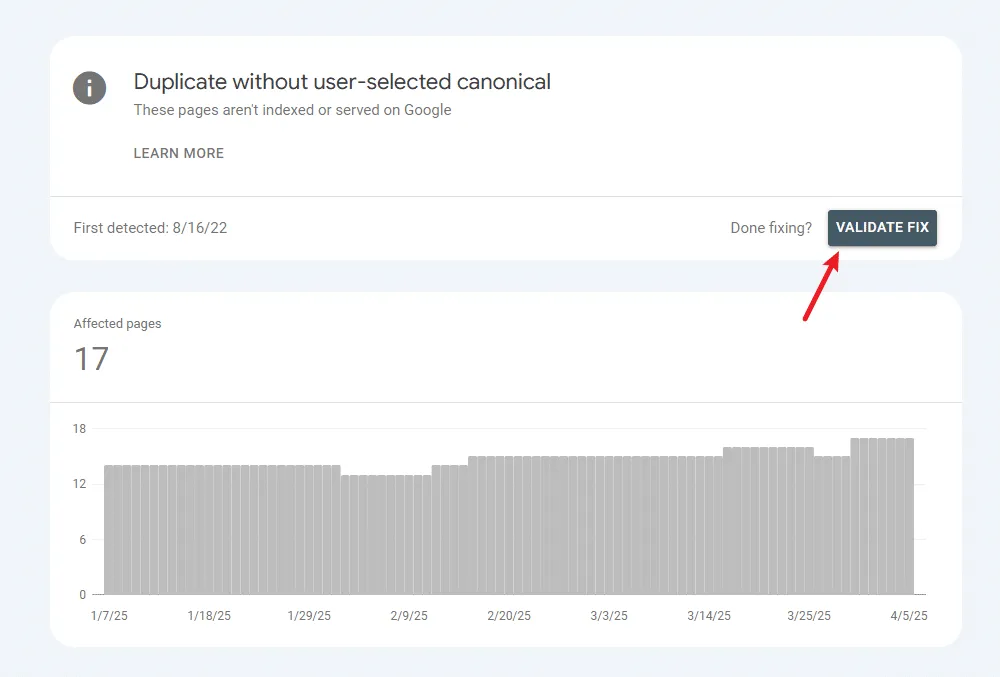
Take into account that GSC reports contain only up to 1000 URLs. Most often, this is enough to give you a representative sample of your problem areas.
If your website is larger, you may find the report doesn’t list ALL problem URLs.
Crawling with Screaming Frog
To get a complete grasp of the problem, you need to perform your own crawl, and that’s where Screaming Frog comes into play.
If you’re looking to audit and analyze your site for SEO, you need Screaming Frog!
Screaming Frog is a crawling tool that lets you explore your website like a search engine, diagnosing your structure, internal linking, indexability, AND canonicalization, among many other things.
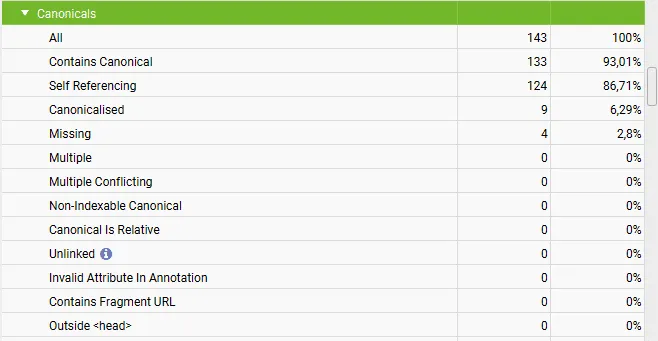
There is an entire section dedicated to canonical link tags. You’ll find reports for all major canonical issues, as shown in the screenshot.
You can download either report as a spreadsheet to use for further processing.
The canonicalized URL report looks like this:
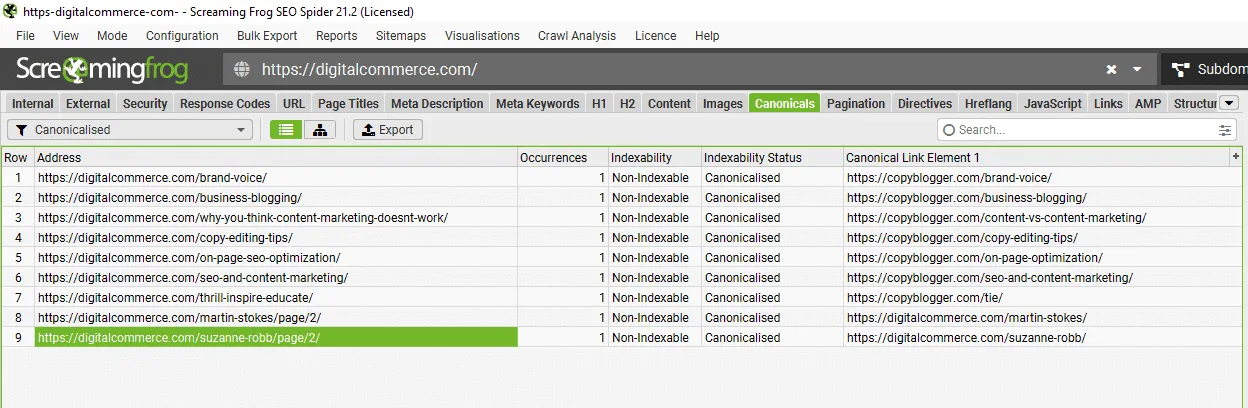
Ours is fairly clean—a few republished blog posts from Copyblogger, and some canonicalized paginated URLs.
As we previously discussed, the latter is not ideal, but it’s also not worth the effort to fix for a couple of author archives.
Manually Inspecting Canonical Tags
My favorite way to check canonicals is to browse the site and see for myself.
I use META SEO Inspector, a powerful Chrome extension that lets me quickly check critical SEO elements on the page I’m viewing.
I use it for checking canonicals and pretty much everything else:
- Meta data
- Open graph
- Structured data
- Heading structures
- And more
It’s one of the tools I use most on a daily basis.
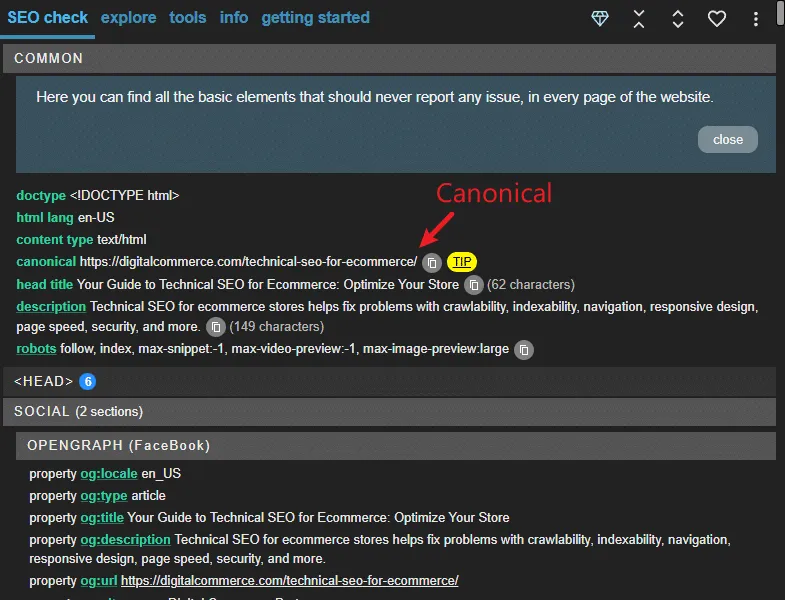
And because we know where to look for canonicalization issues, scanning a site for potential issues is really fast and efficient.
Other Methods to Control Canonicalization and Indexing
The canonical link is not the be-all and end-all of canonicalization. In fact, it’s something Google can and will ignore depending on various factors.
You can use more SEO methods to ensure the correct content is showing in search results and that everything else is not.
Let’s run through them.
301 Redirection
Redirection is typically invisible to users, except for the changing of the URL in the top bar. However, with this simple Chrome extension, you can detect and trace the redirect path that took you to the final URL.
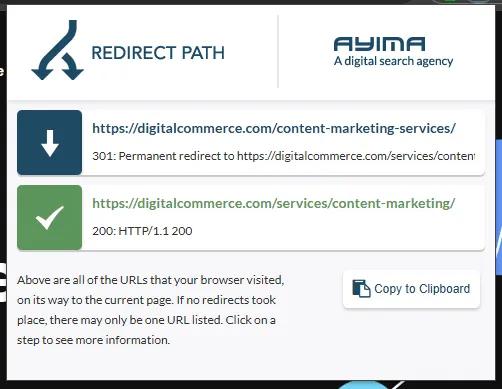
Redirecting a URL is a strong signal that it should not be used as the canonical.
In fact, if you don’t need the duplicate page live, just redirect it. It’s cleaner and more effective than using the canonical.
For example, redirecting is recommended when discerning between technical duplicates like:
- HTTP or HTTPS protocols (use HTTPS, of course):
http://example.com/https://example.com/
- WWW or non-WWW subdomain:
https://www.example.com/https://example.com/
- With or without “/” at the end of the URL:
https://example.comhttps://example.com/
- When duplicate pages exist with uppercase and lowercase letters:
https://example.com/Services/https://example.com/services/
There is no need for all these URLs to exist or be accessible. Just set up the correct redirect rules to eliminate the duplicate content.
If you can’t use a redirect, a self-canonical link will sufficiently control duplicate content in the cases above.
Redirecting is also recommended when migrating or merging content:
Migrating a page from one URL to another
https://example.com/shoe-polishing-services/https://example.com/services/shoe-polishing/
Merging several content pages
https://example.com/blog/how-to-change-a-lightbulb/https://example.com/blog/changing-a-lightbulb-the-ultimate-guide/
Using a 301 permanent redirect is highly recommended as it sends an unmistakable signal to search engines. I have never seen Google using a 301 redirected URL as the canonical version.
A 302 temporary redirect is a weaker canonical signal. I don’t recommend using 302 redirects unless you intend to bring the page back in a very short time frame.
Of course, you don’t want to point a canonical tag to a redirected page…
Sitemap.xml
The sitemap.xml file looks like this:
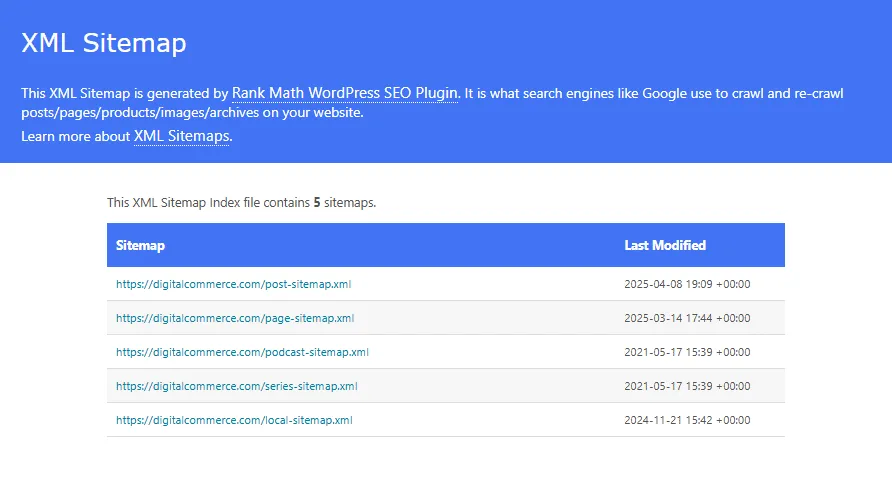
The sitemap is the “official” list of URLs you want to index and participate in search. It’s another signal to Google on how to canonicalize your content.
Here’s what Google says:
“All pages listed in a sitemap are suggested as canonicals; Google will decide which pages (if any) are duplicates, based on similarity of content.
Supplying the preferred canonical URLs in the sitemaps is a simple way of defining canonicals for a large site, and sitemaps are a useful way to tell Google which pages you consider most important on your site.”
Make sure all canonical links are present in the sitemap. Ensure that all listed URLs use a consistent format.
And remove all URLs you don’t want indexed:
- Canonicalized URLs
- Redirected URLs
- URLs returning 4xx / 5xx errors
- URLs that have a nofollow robots directive
- URLs that are blocked in Robots.txt
The Meta Robots Tag
The meta robots tag looks like this:
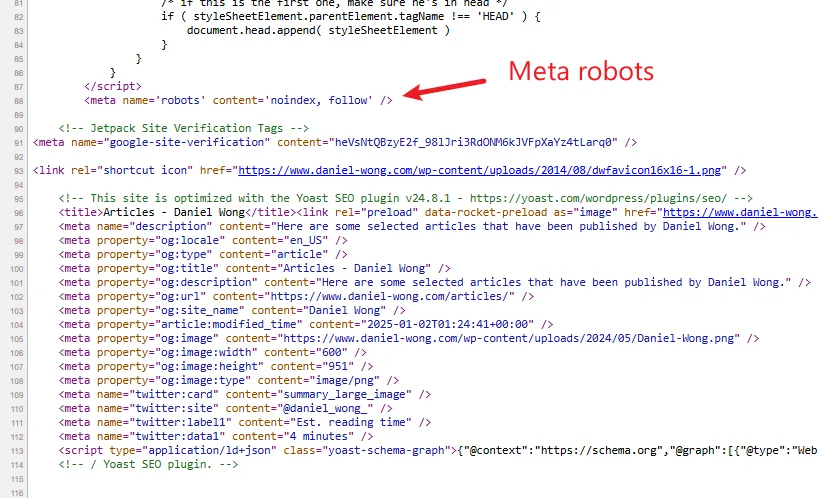
We use it when we don’t want a page to participate in search AT ALL.
Unlike the canonical link, the meta robots tag IS a directive. Do not apply sitewide! Incorrect implementation can drop your site from search as soon as the next crawl.
Here’s what Google says:
“We don’t recommend using noindex to prevent selection of a canonical page within a single site, because it will completely block the page from Search. rel=“canonical” link annotations are the preferred solution.”
This means you DON’T want to use noindex on pages that can otherwise be canonicalized:
- Product variants
- Category URLs with tags or filters
- Tracking URLs
- Slash, WWW, or HTTP variants
That said, you can use noindex to remove specific pages from your site that are not beneficial for search, like:
- Strictly functional pages like:
- Cart
- Checkout
- Search
- Policy pages:
- Privacy policy
- Terms and Conditions
- GDPR-related pages, etc
- Landing pages and conversion funnel elements:
- Ads, email, and other forms of marketing
- Signup forms, thank you pages, etc.
- Certain archives and taxonomies:
- Tags
- Image attachment pages
- Date archives
I always use meta robots with the follow value, like so:
<meta name=”robots” content=”noindex,follow”>There is almost never a reason to prevent crawlers from following links on an entire page. Sponsored or affiliate links can be made nofollow directly in the <a> tag on an individual basis.
Nofollowing a whole page, or worse, a section of pages, just sends crawlers into a dead end.
This is rarely a problem with WordPress sites, but in Shopify, noindex and nofollow go hand in hand by default. You can have either:
- content=”index, follow” OR
- content=”noindex, nofollow”
You can modify this behavior with some SEO apps, but not natively in Shopify.
Obviously, you don’t want to point a canonical tag towards a page with noindex.
Internal Linking and Navigation
I can’t stress this enough: good internal linking is foundational for every website.
Pick one version of your URL and use that everywhere:
- Menus and navigation
- Header
- Footer
- Mobile
- Category pages
- Supplementary navigation:
- Related posts/products
- Breadcrumbs
- Meta
- Canonical link
- OG link
- Manual links (in body content)
- Sitemap
Good internal linking allows both spiders and users to discover and access content naturally and without extra steps.
Doing so consistently will help search engines understand which URL is the canonical, and which versions are pure technical duplicates.
Bad internal linking will force bots to skip around several URLs before reaching the final destination. This wastes resources and introduces error and confusion as to which URL should be used for indexing and ranking.
Robots.txt
The robots.txt file controls what content spiders can and cannot access on your site. Any URL or URL structure listed in the file is forbidden for entry.
If crawlers can’t access, they can’t read, index, or rank this content.
We’ve had clients go through a bad site migration, resulting in the robots.txt blocking the entire site for search engines. Search performance dropped like a stone, and even after recovery, there were long-lasting consequences.
It’s best if you leave your robots.txt alone unless absolutely necessary.
Think of the Planet and Your Rankings. Fix Duplicate Content!
Okay, that’s canonicalization. All of it!
What did we learn?
Duplicate content is nothing but carbon emissions. It clogs up crawlers, wastes resources and energy, and pollutes the SERP. And it’s costing you search traffic!
Unfortunately, duplicate content is also a technical byproduct of many modern content management systems. Sometimes, you can fix some of it. But more often, you just have to live with it.
Canonicalization gives you a scalable way to take control, clean up your index, and make life easier for both users and search engines.
But it’s just one piece of the puzzle. On top of canonicalization, our Website Health Audit includes over 80 individual checks covering usability, on-page SEO, and technical setup.
So, if you need help with duplicate content or any other technical SEO issue, check out our Technical SEO Services page.
Let’s get your site running at full strength!